There are thousands of charts on ourworldindata.org. The breadth of topics is impressive: demography, poverty, nutrition, climate change, human rights, you name it. In this post, I generate a data set that contains the titles of all these charts, and perform some descriptive analyses on it. The goal is to provide a representation of what the major themes are and how they are tied together.
We start by scraping the list of plot titles from here, and structuring the resulting data in such a way that it is possible to compute how many graphs are associated to each theme. In other words, we would like to create a data.frame (or a tibble) like the following:
Theme
Graph Title
Access to Energy
Number of people with and without access to clean cooking fuels
Access to Energy
Number of people without access to clean fuels for cooking
Access to Energy
People without clean fuels for cooking, by world region
Access to Energy
Share of the population without access to clean fuels for cooking
Access to Energy
Share with access to electricity vs. per capita energy consumption
Age Structure
Adolescent birth rate, 10-14 year olds
Age Structure
Adolescent birth rate, 15-19 year olds
Age Structure
Age dependency breakdown by young and old dependents
Age Structure
Age dependency ratio
…
…
Code
library(tidyverse)library(tidytext)library(rvest)library(widyr)library(textstem)library(data.table)library(igraph)library(ggraph)remove(list =ls(all = T))url <-"https://ourworldindata.org/charts"webpage <-read_html(url)titles_href <- webpage %>%html_nodes("a") %>%html_attr("href") %>%as.data.frame() %>%setNames("titles_href")titles_text <- webpage %>%html_nodes("a") %>%html_text() %>%as.data.frame() %>%setNames("titles_text") %>%mutate(nchar =nchar(titles_text))titles <-bind_cols(titles_href, titles_text)# Graphs start at row 258 and end at row 6689titles <- titles[258:6689, ]# The problem is that we don't know what sections these graphs belong to # We can scrape sections in the same waysection_id <- webpage %>%html_nodes("h2") %>%html_attr("id") %>%as.data.frame() %>%setNames("section_id") section_text <- webpage %>%html_nodes("h2") %>%html_text() %>%as.data.frame() %>%setNames("section_text")sections <-bind_cols(section_id, section_text)# How do we map this information?# I copy the xpath of access-to-energy section_xpath <-"/html/body/main/div/div/div[2]/div/section[2]"# Extract the nodes from the selected section using XPathgraphs_section <- webpage %>%html_node(xpath = section_xpath) %>%# Target the specific sectionhtml_nodes("a") %>%# Assuming the graphs are linked within <a> tags; adjust as needed html_text %>%# Extract URLs of the graphsna.omit() # Remove any NA values###graphs_selector <-function(xpath){graph_titles <- webpage %>%html_node(xpath = xpath) %>%# Target the specific sectionhtml_nodes("a") %>%# Assuming the graphs are linked within <a> tags; adjust as needed html_text %>%# Extract URLs of the graphsna.omit() %>%# Remove any NA valuesas.data.frame() %>%setNames("graph_title")return(graph_titles)}###sections <- sections %>%mutate(xpath =paste0("/html/body/main/div/div/div[2]/div/section[", 1:203, "]")) %>%slice(2:203)sections_list <- sections %>%pull(xpath)results <-lapply(sections_list, function(xpath) {graphs_selector(xpath)})names(results) <- sections$section_textbound_results <-rbindlist(results, idcol = T) %>%rename(theme = .id)
After having done so, we simply count how many graphs are included in each of theme (n), how much each theme weighs on the total number of graphs (Share), and rank it according to that (Rank).
Without wanting to alienate laymen, we compute some summary statistics right off the bat. This is admittedly slightly more technical then what I was aiming for when I started writing this post. However, I wanted to show that one can infer a lot from seemingly unassuming statistic measures, and support these insights with data visualisation. Proceding the other way around — i.e. exploring the data through graphs first — is, obviously, also legitimate: what works best depends, as it is often the case, from the context on operates in.
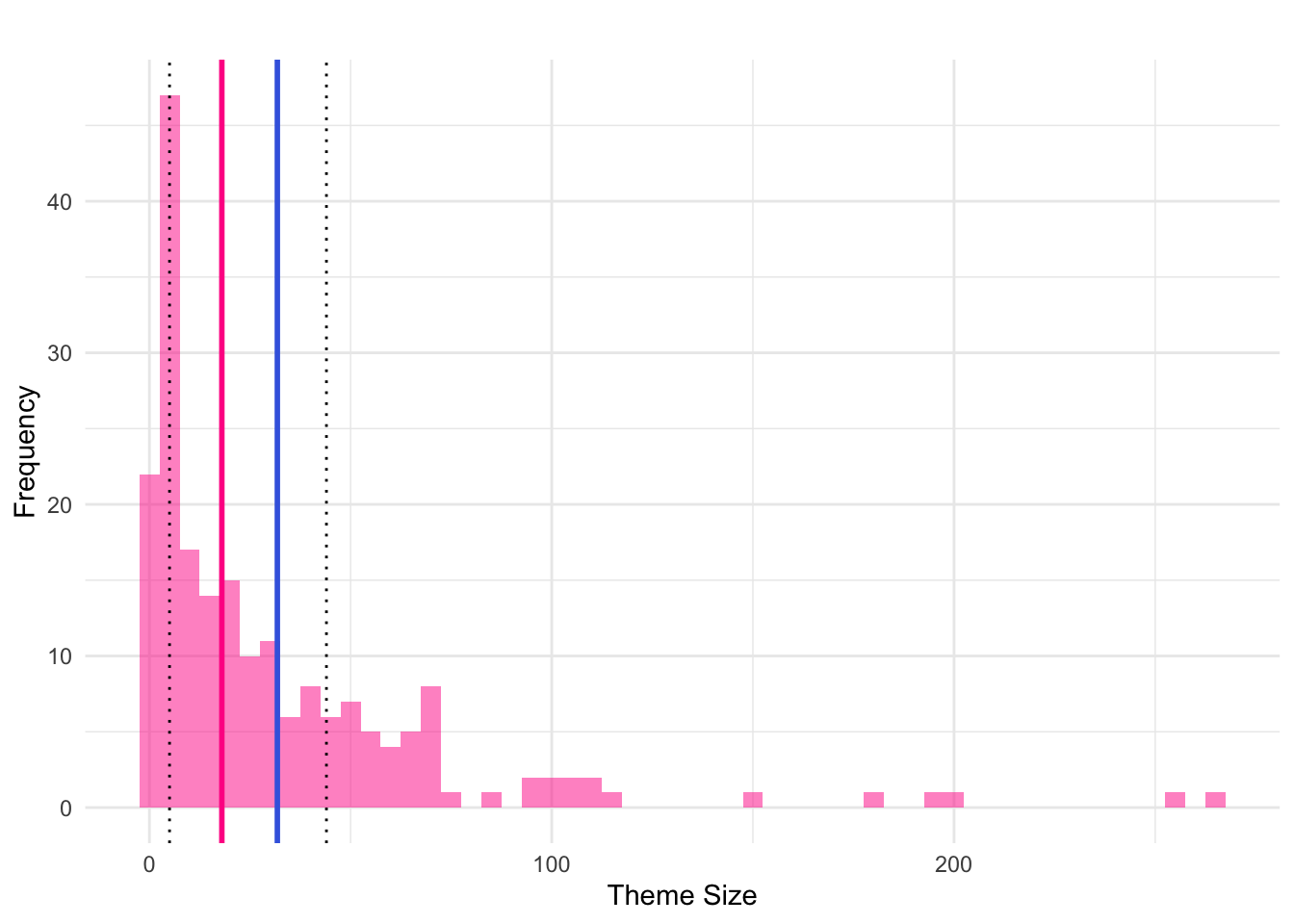
Let us focus on the n variable. There are a total of 202 themes. On average, each theme contains approximately 32 graphs. The maximum number of graphs per theme is 263, which is several standard deviations (SD = 41.68) away from the mean, indicating the presence of outliers. The median is lower than the mean, which suggests that the distribution of theme sizes is skewed to the right — imagine an uneven bell curve with a peak on the left and a tail stretching to the right. This shape is confirmed by the first and third quartile (Q25 = 5, Q75 = 43.50): the first quartile implies that the first 25% of all themes contain 5 or fewer graphs; the third indicates that 75% of all themes have 43.50 graphs or fewer. This threshold is about a quarter of a standard deviation from the mean and about half a standard deviation from the median, suggesting that most values fall below Q75.
We finally plot the distribution of theme sizes. I generate a histogram where each bar represents the frequency of theme sizes, and set a bin width of 5. The dotted lines represent Q25 and Q75; the pink line represents the mean, the blue the median.
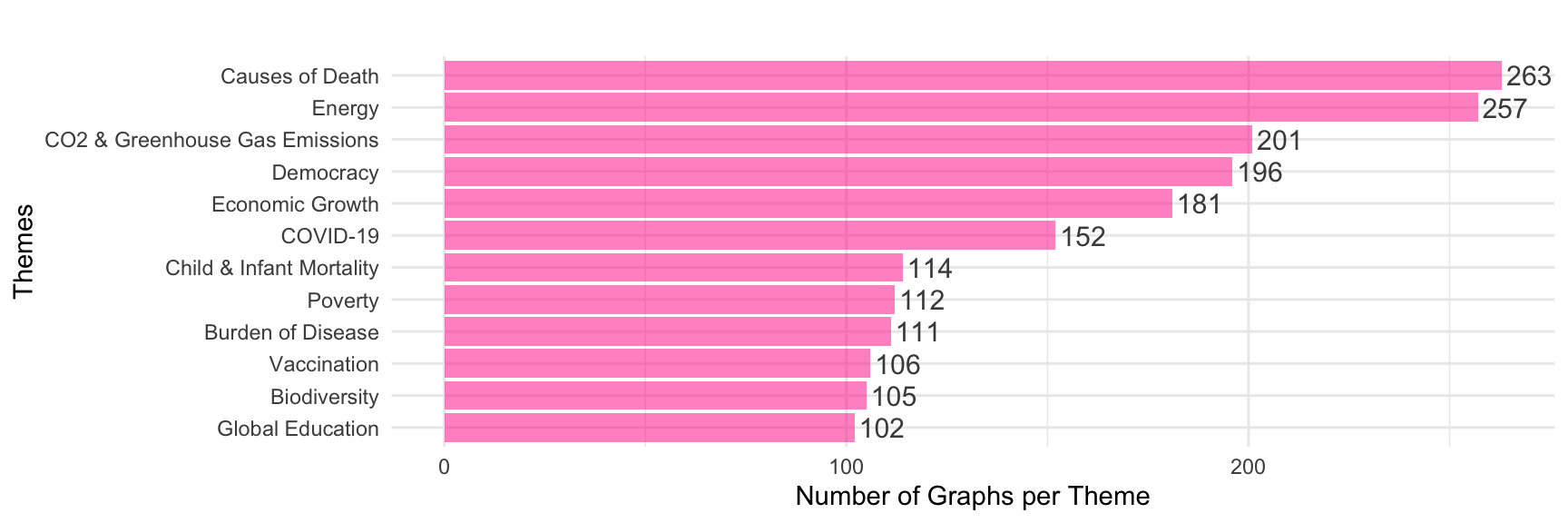
We now turn to the 10 most relevant themes, i.e. those short bars that you see on the righthand side of the previous graph.
Theme
n
Share
Rank
Causes of Death
263
4.10
1
Energy
257
4.00
2
CO2 & Greenhouse Gas Emissions
201
3.13
3
Democracy
196
3.05
4
Economic Growth
181
2.82
5
COVID-19
152
2.37
6
Child & Infant Mortality
114
1.78
7
Poverty
112
1.74
8
Burden of Disease
111
1.73
9
Vaccination
106
1.65
10
Taken together, they account for roughly a fourth of all graphs. The three most important ones relate to Causes of Death, Energy, and CO2 Emissions and represent 12% of the total number of graphs on ourworldindata.org/charts. One may want to plot the actual number of graphs per theme in a bar chart using the following snippet.
Code
themes %>%filter(n >100) %>%ggplot(aes(y =reorder(theme, n), x = n)) +geom_bar(stat ="identity", fill ="#FF1493", size = .15, alpha =0.5) +geom_text(aes(label = n), hjust =-0.1, color ="#49494a", size =4) +labs(title ="", y ="Themes", x ="Number of Graphs per Theme") +theme_minimal()
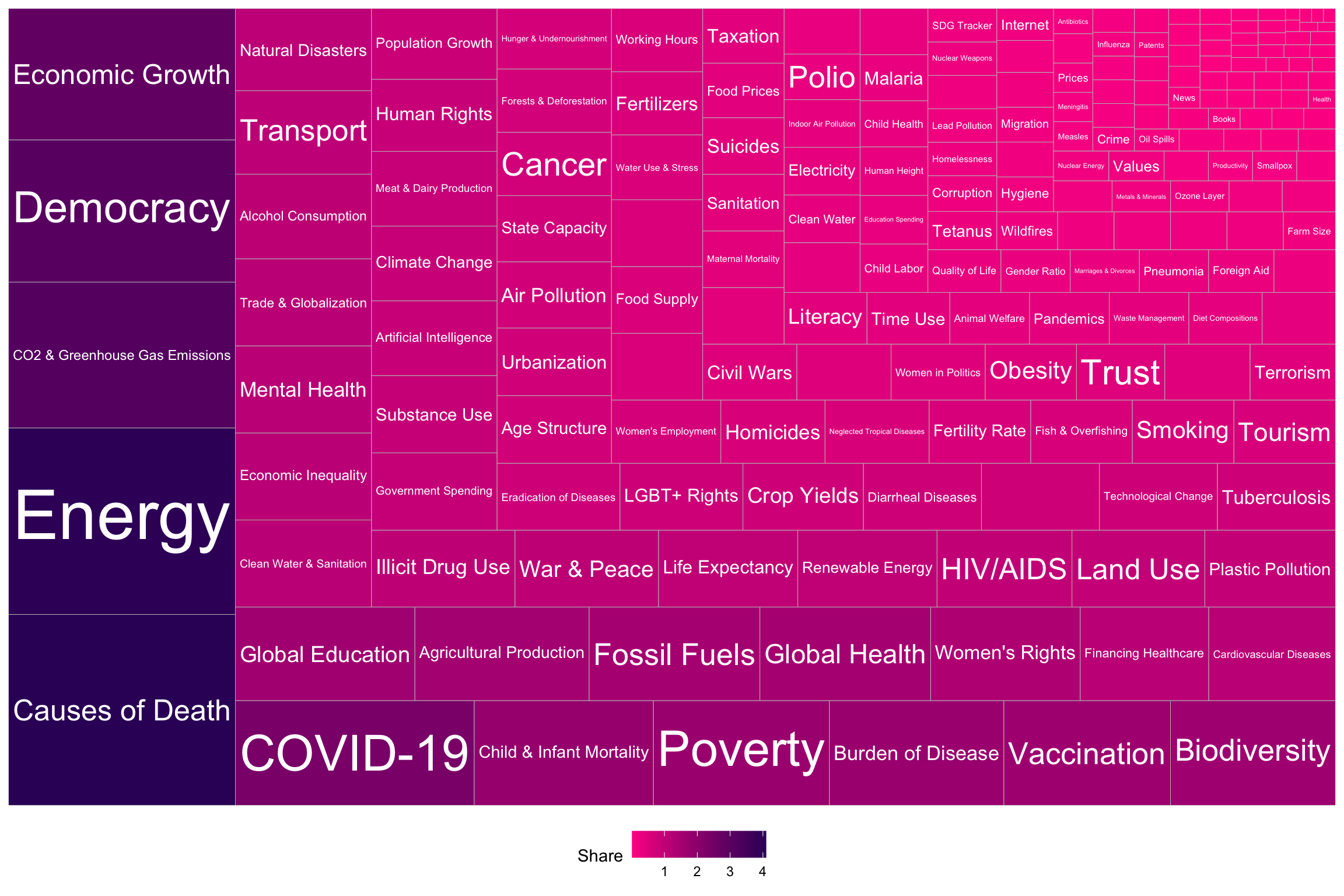
However, the sheer number of themes (N = 202) would make the plot look too crammed if I did not truncate the data by selecting the themes that contains more than 100 graphs. Why not getting funkier and resorting to a tree map instead? This is a very informative visualization technique because it gives a better grasp of themes, their labels, and their proportions. To be honest, it is also way catchier!
While some themes inevitably get more attention, the bottom line is that ourworldindata.org really does deal with a large a variety of topics!
One could classify information less granularly and present a more aggregate, yet useful, picture. I make use of the 10 categories that appear in the navigation bar of ourworldindata.org when clicking on “Browse by topic”. I then map them onto the graph themes that we have seen above, focusing on groups that count more than 20 elements. The following donut chart displays the relative weight of each category in terms of how many graphs it contains.
Code
aggreagte_picture <-read.csv("categorised_themes_ourworldindata.csv") %>%mutate(across(where(is.character), str_trim)) %>%group_by(category) %>%summarise(share =sum(share), n =sum(n)) %>%ungroup() %>%mutate(rank =dense_rank(desc(n)))# sum(aggreagte_picture$share) # We have retrieved 87% of the shares by considering only themes that group # more that 20 graphs.data <- aggreagte_picture %>%mutate(csum =rev(cumsum(rev(share))), ymin = csum - share, ymax = csum) %>%arrange(desc(category)) %>%mutate(midpoint = (ymin + ymax) /2,label_x =3.5, # x position for labelslabel_y = midpoint) # y position for labelscustom_palette <-c("#f72585ff","#b5179eff","#4cc9f0ff","#7209b7ff","#560badff","#480ca8ff","#3f37c9ff","#4361eeff","#4895efff","#3a0ca3ff")# ggplot(data, aes(ymax = ymax, ymin = ymin, xmax = 4, xmin = 3, fill = category)) +# geom_rect() +# coord_polar(theta = "y") +# scale_fill_manual(values = custom_palette) +# xlim(c(2, 4)) +# theme_void() +# theme(legend.position = "right",# plot.margin = margin(0, 0, 0, 0),# panel.margin = margin(0, 0, 0, 0)) +# labs(fill = "Category") +# geom_text(aes(x = label_x, y = label_y, label = n), color = "white", size = 4, hjust = 0.5)# # ggsave("donut_chart.png", width = 10, height = 10)# library(packcircles)## adata <- data.frame(category=paste("Group", letters[1:20]), n=sample(seq(1,100),20)) # apacking <- circleProgressiveLayout(adata$n, sizetype='area')# adata <- cbind(adata, apacking)# adat.gg <- circleLayoutVertices(apacking, npoints=50)# # ggplot() + # geom_polygon(data = adat.gg, aes(x, y, group = id, fill=as.factor(id)), colour = "black", alpha = 0.6) +# geom_text(data = adata, aes(x, y, size=n, label = category)) +# scale_size_continuous(range = c(1,4)) +# theme_void() + # theme(legend.position="none") +# coord_equal()## data <- data %>% select(category, n)# packing <- circleProgressiveLayout(data$n, sizetype='area')# data <- cbind(data, packing)# dat.gg <- circleLayoutVertices(packing, npoints=50)# # custom_palette <- c(# "#FF69B4", # Hot Pink# "#FF1493", # Deep Pink# "#DDA0DD", # Plum# "#DA70D6", # Orchid# "#BA55D3", # Medium Orchid# "#9370DB", # Medium Purple# "#8A2BE2", # Blue Violet# "#4B0082", # Indigo# "#4169E1", # Royal Blue# "#0000FF" # Blue# )# # ggplot() + # geom_polygon(data = dat.gg, aes(x, y, group = id, fill=as.factor(id)), colour = "black", alpha = 0.8) +# geom_text(data = data, aes(x, y, size=n, label = category)) +# scale_size_continuous(range = c(1,4)) +# scale_fill_manual(values = custom_palette) +# theme_void() + # theme(legend.position="none") +# coord_equal()
Frequent words
Now that we have all the graph titles, it may be worth counting how often words appear. We remove stop words and lemmatise them, too: this is relevant because very few people would care about how many times the words of and the appear. Similarly it makes sense to consider singular and plural forms as one, e.g. country and countries.
Code
word_counts <- bound_results %>%select(graph_title) %>%unnest_tokens(word, graph_title) %>%# Tokenize wordsanti_join(stop_words, by ="word") %>%# Remove stop wordsmutate(word_2 =lemmatize_words(word)) %>%count(word_2, sort =TRUE) # Count words and sort by frequency
The 5 most recurring words are: share, death, rate, capita, and GDP. 3 of these words (e.g. share, rate, capita) suggest that most graphs contain some sort of comparative element.
Are these positive or negative words?
Why not performing some rudimentary version of sentiment analysis on them? Of course this is somewhat of a stretch because we are not dealing with actual sentences. The same word can have different meanings depending on what precedes or follows it. Similarly, there is a certain degree of subjectivity – words might sound differently to different people. While it would feel pointless to identify the emotional tone of a neutral title, one could still try to figure out what proportion of words are perceived as related to inherently negative or positive feelings. To do that, we evaluate the emotional color of words using the Bing method. It associates a binary positive/negative quality to each word.
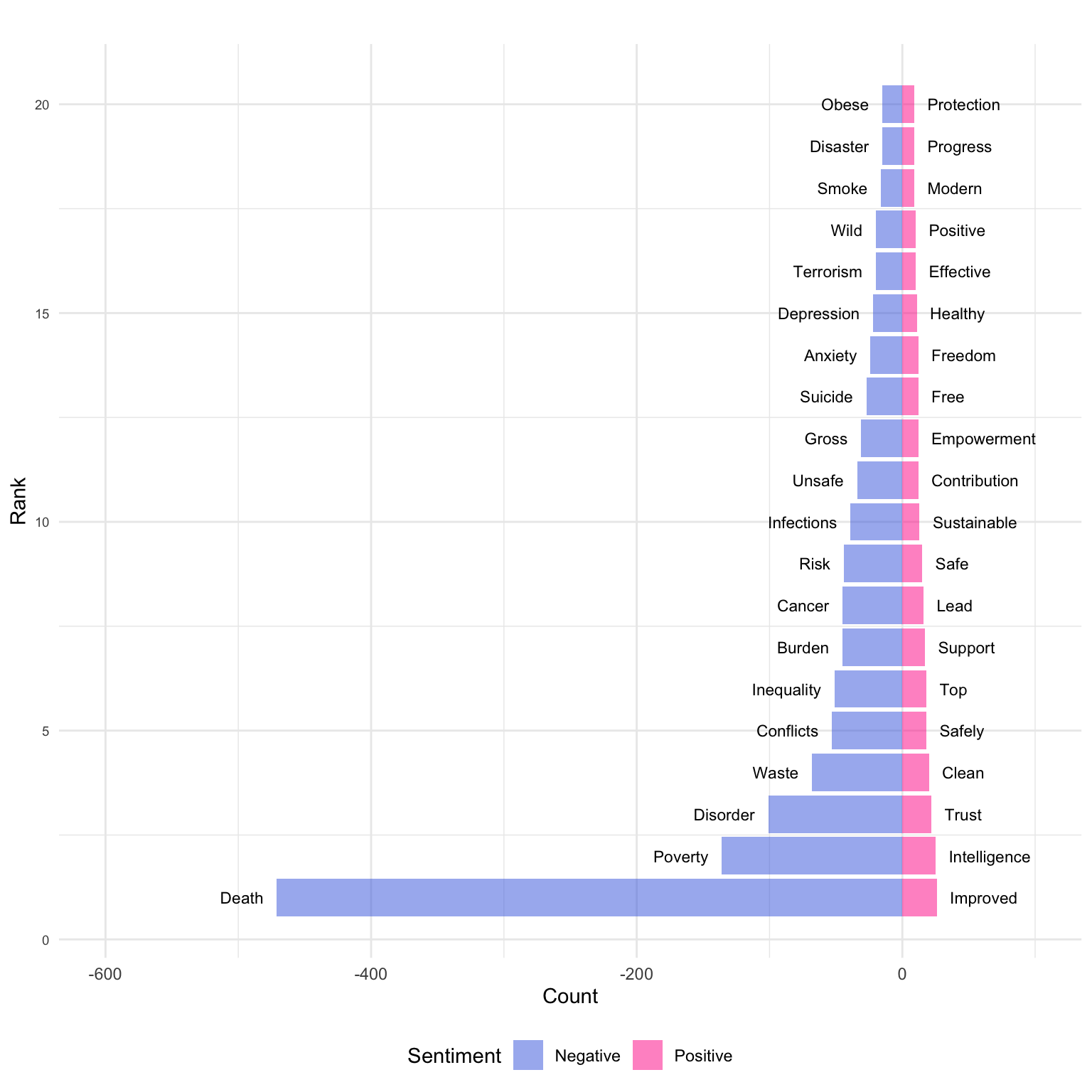
We then create a pyramid plot that shows how frequently the 20 most common positive and negative words occur.
Code
positive_words <- positive_words %>%slice(1:20) %>%mutate(type ="Positive") %>%mutate(rank =row_number())negative_words <- negative_words %>%slice(1:20) %>%mutate(type ="Negative") %>%mutate(rank =row_number())sentiment_words <- positive_words %>%bind_rows(negative_words) %>%mutate(n =case_when( type =="Negative"~- n,TRUE~ n ))# Plot the pyramid chartggplot(sentiment_words, aes(x = rank, y = n, fill = type)) +geom_bar(stat ="identity", alpha =0.5) +geom_text(aes(label =str_to_title(word), y = n +ifelse(type =="Negative", -10, 10)),size =3, hjust =ifelse(sentiment_words$type =="Positive", 0, 1)) +scale_y_continuous(name ="Count", breaks =seq(-500, 500, 50), labels =abs(seq(-500, 500, 50))) +scale_fill_manual(name ="Sentiment", values =c("Positive"="#FF1493", "Negative"="royalblue" )) +coord_flip() +labs(x ="Rank", y ="Count", title ="") +ylim(-600, 100) +theme_minimal() +theme(legend.position ="bottom", axis.text.y =element_text(size =7))
The pyramid shows that the number of words with a positive connotation is much lower – no wonder Economics was known as the dismal science! In other words, there is a tendency to focus on topics that are perceived as somewhat gloomier. Not only: given that bars are ordered by rank (in ascending order, top to bottom), this chart also makes clear that the most frequent negative word is much more common than the most frequent positive one. This does not mean that the folks at ourworldindata.org are a bunch of pessimists. One can be an optimist and talk about themes that are mostly perceived as negative: after all, absolute poverty has been on the decline for decades, child mortality is incomparably lower today than it was during the Industrial Revolution, and GDP per capita skyrocketed during the 20th century. While there is reason to believe that Malthus is still wrong, this is not to say that there are no challenges ahead.
A network of words
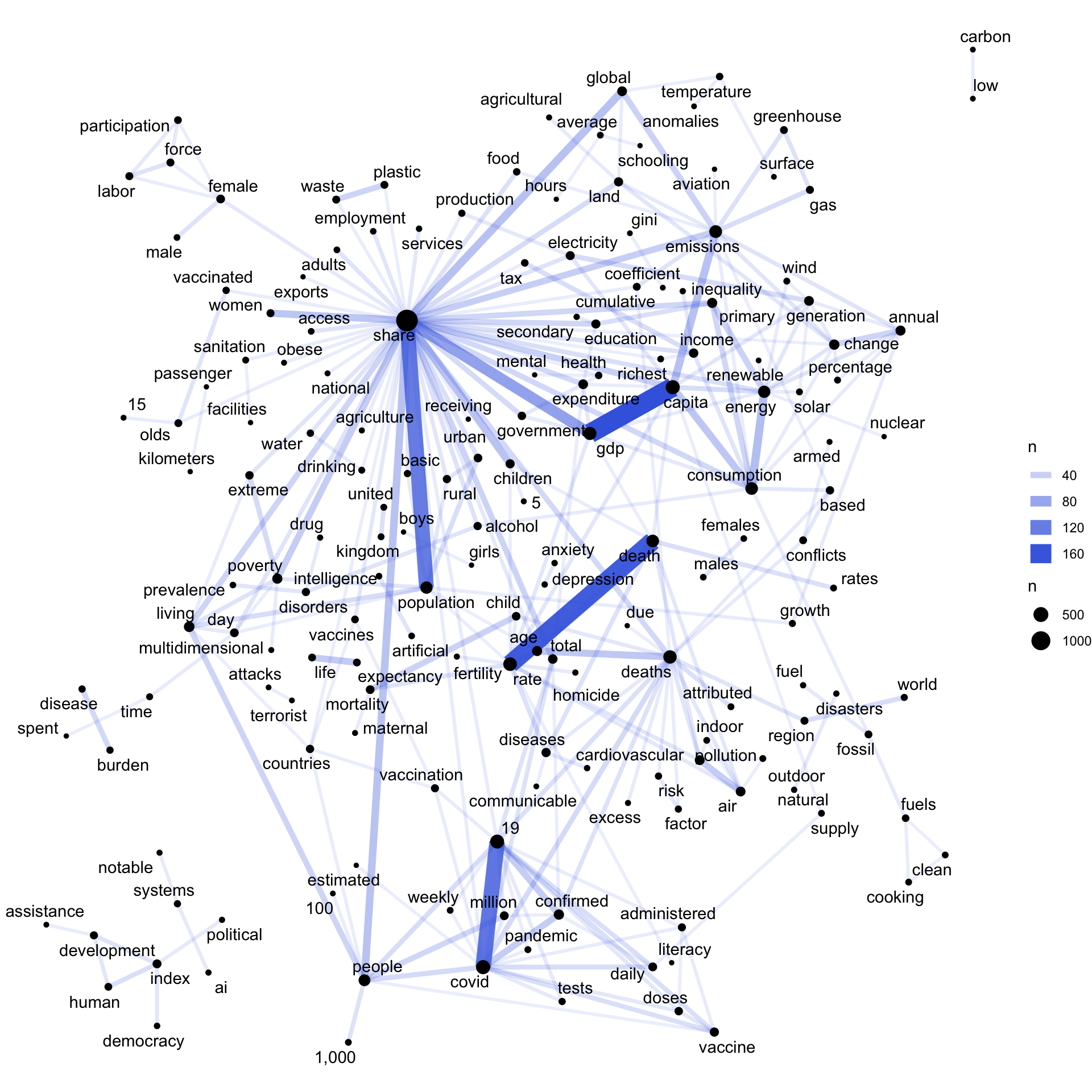
We can also use these data to explore some concepts in network analysis. Let us consider all the corpus of graph titles. How often do words appear together? How do they relate to each other? Are there any clusters of words that stand out? Let us do that visually.
Each vertex is scaled according to how often each word appears. Links are larger and darker depending on how often word pairs are found together. The word share is, as we saw earlier, very central. It often tandems with population, children, living, people, and GDP, cutting through all categories. GDP is tightly tied to capita, death to rate.
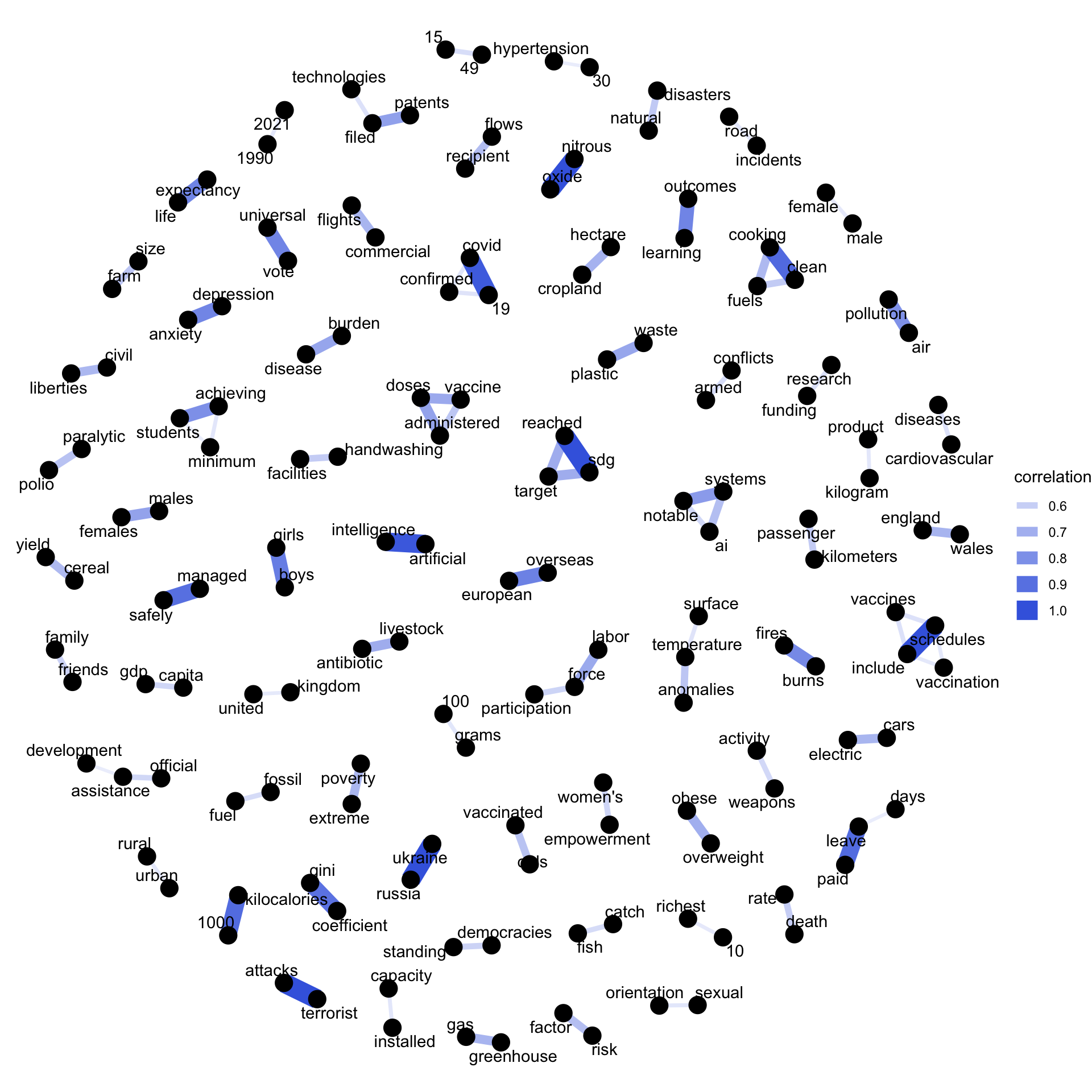
We can also show clusters that have a minimum level of correlation, i.e. words that are almost invariably found together.
---title: "Ourworldindata as Data"description: "From Graph Titles to Networks"author: - name: Gaspare Tortorici url: www.gasparetortorici.infodate: 08-09-2024categories: [Data Analysis, Web Scraping, Networks, R] citation: url: to-be-definedimage: network.jpgformat: html: code-fold: true code-tools: source: true toggle: true caption: noneeditor: visualdraft: false # Change this if you don't want the article to appear---## Graph Titles, Themes, and SentimentsThere are thousands of charts on [ourworldindata.org](https://ourworldindata.org/). The breadth of topics is impressive: demography, poverty, nutrition, climate change, human rights, you name it. In this post, I generate a data set that contains the titles of all these charts, and perform some descriptive analyses on it. The goal is to provide a representation of what the major themes are and how they are tied together.We start by scraping the list of plot titles from [here](https://ourworldindata.org/charts), and structuring the resulting data in such a way that it is possible to compute how many graphs are associated to each theme. In other words, we would like to create a `data.frame` (or a `tibble`) like the following:| Theme | Graph Title ||------------------|--------------------------------------------------------------------|| Access to Energy | Number of people with and without access to clean cooking fuels || Access to Energy | Number of people without access to clean fuels for cooking || Access to Energy | People without clean fuels for cooking, by world region || Access to Energy | Share of the population without access to clean fuels for cooking || Access to Energy | Share with access to electricity vs. per capita energy consumption || Age Structure | Adolescent birth rate, 10-14 year olds || Age Structure | Adolescent birth rate, 15-19 year olds || Age Structure | Age dependency breakdown by young and old dependents || Age Structure | Age dependency ratio || ... | ... |: {.striped .hover}```{r setup, include = FALSE}knitr::opts_chunk$set(message =FALSE)``````{r}#| warning: falselibrary(tidyverse)library(tidytext)library(rvest)library(widyr)library(textstem)library(data.table)library(igraph)library(ggraph)remove(list =ls(all = T))url <-"https://ourworldindata.org/charts"webpage <-read_html(url)titles_href <- webpage %>%html_nodes("a") %>%html_attr("href") %>%as.data.frame() %>%setNames("titles_href")titles_text <- webpage %>%html_nodes("a") %>%html_text() %>%as.data.frame() %>%setNames("titles_text") %>%mutate(nchar =nchar(titles_text))titles <-bind_cols(titles_href, titles_text)# Graphs start at row 258 and end at row 6689titles <- titles[258:6689, ]# The problem is that we don't know what sections these graphs belong to # We can scrape sections in the same waysection_id <- webpage %>%html_nodes("h2") %>%html_attr("id") %>%as.data.frame() %>%setNames("section_id") section_text <- webpage %>%html_nodes("h2") %>%html_text() %>%as.data.frame() %>%setNames("section_text")sections <-bind_cols(section_id, section_text)# How do we map this information?# I copy the xpath of access-to-energy section_xpath <-"/html/body/main/div/div/div[2]/div/section[2]"# Extract the nodes from the selected section using XPathgraphs_section <- webpage %>%html_node(xpath = section_xpath) %>%# Target the specific sectionhtml_nodes("a") %>%# Assuming the graphs are linked within <a> tags; adjust as needed html_text %>%# Extract URLs of the graphsna.omit() # Remove any NA values###graphs_selector <-function(xpath){graph_titles <- webpage %>%html_node(xpath = xpath) %>%# Target the specific sectionhtml_nodes("a") %>%# Assuming the graphs are linked within <a> tags; adjust as needed html_text %>%# Extract URLs of the graphsna.omit() %>%# Remove any NA valuesas.data.frame() %>%setNames("graph_title")return(graph_titles)}###sections <- sections %>%mutate(xpath =paste0("/html/body/main/div/div/div[2]/div/section[", 1:203, "]")) %>%slice(2:203)sections_list <- sections %>%pull(xpath)results <-lapply(sections_list, function(xpath) {graphs_selector(xpath)})names(results) <- sections$section_textbound_results <-rbindlist(results, idcol = T) %>%rename(theme = .id)```After having done so, we simply count how many graphs are included in each of theme category (*n*), how much each theme weighs on the total number of graphs (*Share*), and rank them according to that (*Rank*).```{r}themes <- bound_results %>%group_by(theme) %>%count(sort = T) %>%ungroup() %>%mutate(share = n/length(bound_results$graph_title)*100) %>%mutate(rank =dense_rank(desc(n)))```Without wanting to alienate laymen, we compute some summary statistics right off the bat. This is admittedly slightly more technical then what I was aiming for when I started writing this post. However, I wanted to show that one can infer a lot from seemingly unassuming statistic measures, and support these insights with data visualisation. The other way around is, obviously, also legitimate: what works best depends, as it is often the case, from the context.```{r}summary_stats <- themes %>%summarize(across(c("n", "share"),list(mean =~mean(.x, na.rm =TRUE),median =~median(.x, na.rm =TRUE),sd =~sd(.x, na.rm =TRUE),min =~min(.x, na.rm =TRUE),max =~max(.x, na.rm =TRUE),q25 =~quantile(.x, 0.25, na.rm =TRUE),q75 =~quantile(.x, 0.75, na.rm =TRUE),count =~n() ), .names ="{col}%{fn}")) %>%mutate(across(where(is.numeric), ~round(., 2)))tidy_summary <- summary_stats %>%pivot_longer(everything(), names_to =c("variable", "statistic"), names_sep ="%", values_to ="value") %>%pivot_wider(names_from ="statistic")```| Variable | Mean | Median | SD | Min | Max | Q25 | Q75 | Count ||----------|-------|--------|-------|------|------|------|-------|-------|| n | 31.81 | 18.00 | 41.68 | 1 | 263 | 5.00 | 43.50 | 202 || Share | 0.50 | 0.28 | 0.65 | 0.02 | 4.09 | 0.08 | 0.68 | 202 |Let us focus on the *n* variable. There is a grand total of 202 themes. The average number of graphs per theme is roughly 32. The maximum (263) is several SD away from the mean, pointing to the presence of outliers. The median is lower than the mean, suggesting that theme sizes are skewed to the right -- picture an uneven bell curve with the high part on the left and a tail that stretches to the right. This shape is confirmed by Q25 (the first quartile) and Q75 (the third quartile): the former suggests that 25% of the themes contains 5 or less graphs; the latter indicates that 75% of the observations are less than or equal to 43.50. That threshold is about a fourth of a SD away from the mean, and about half a SD away from the median, indicating that the majority of the values must fall below Q75.We finally plot the distribution of theme sizes. I generate a histogram where each bar represents how frequently value happens, and set a bin width of 5.```{r}#| warning: falseggplot(themes, aes(x = n)) +geom_histogram(binwidth =5, fill ="#FF1493", alpha =0.5) +# geom_density(alpha = 0.1, fill = "#FF1493") +geom_vline(xintercept =mean(themes$n, na.rm = T), col ="royalblue", size =1) +geom_vline(xintercept =median(themes$n, na.rm = T), col ="#FF1493", size =1) +geom_vline(xintercept =quantile(themes$n, probs =0.25, na.rm =TRUE), col ="black", size =0.5,linetype ="dotted") +geom_vline(xintercept =quantile(themes$n, probs =0.75, na.rm =TRUE), col ="black", size =0.5, linetype ="dotted") +labs(title ="",x ="Theme Size",y ="Frequency") +theme_minimal()```We now turn to the 10 most relevant themes, i.e. those short bars that you see on the righthand side of the previous graph.| Theme | n | Share | Rank ||--------------------------------|-----|-------|------|| Causes of Death | 263 | 4.10 | 1 || Energy | 257 | 4.00 | 2 || CO2 & Greenhouse Gas Emissions | 201 | 3.13 | 3 || Democracy | 196 | 3.05 | 4 || Economic Growth | 181 | 2.82 | 5 || COVID-19 | 152 | 2.37 | 6 || Child & Infant Mortality | 114 | 1.78 | 7 || Poverty | 112 | 1.74 | 8 || Burden of Disease | 111 | 1.73 | 9 || Vaccination | 106 | 1.65 | 10 |: {.striped .hover}Taken together, they account for roughly a fourth of all graphs. The three most important ones relate to Causes of Death, Energy, and CO2 Emissions. They represent 12% of the total number of graphs on [ourworldindata.org/charts](https://ourworldindata.org/charts). One may want to plot the actual number of graphs per theme in a bar chart using the following snippet.```{r}#| warning: false#| fig-width: 9#| fig-height: 3themes %>%filter(n >100) %>%ggplot(aes(y =reorder(theme, n), x = n)) +geom_bar(stat ="identity", fill ="#FF1493", size = .15, alpha =0.5) +geom_text(aes(label = n), hjust =-0.1, color ="#49494a", size =4) +labs(title ="", y ="Themes", x ="Number of Graphs per Theme") +theme_minimal()```However, the sheer number of themes (N = 202) would make the plot look too crammed if I did not truncate the data by selecting the themes that contains more than 100 graphs. But why not getting funkier and resorting to a tree map? This is a very informative data visualization technique because it gives a better grasp of theme data, themes, and proportions. To be honest, it is also way catchier.While some themes inevitably get more attention, the bottom line is that [ourworldindata.org](https://ourworldindata.org/) really does deal with a large a variety of topics!```{r}#| warning: false#| fig-align: center#| fig-width: 12#| fig-height: 8library(treemapify)ggplot(themes, aes(area = share, fill = share, label = theme)) +geom_treemap() +geom_treemap_text(color ="white", place ="centre", grow = T) +theme(legend.position ="none") +scale_fill_gradient2("Share", low ="#360167", mid ="#FF1493", high ="#360167", midpoint =0) +theme(legend.position ="bottom")```### A less granular classificationOne could classify information less granularly and present a more aggregate, yet useful, picture. I make use of the 10 categories that appear in the navigation bar of [ourworldindata.org](https://ourworldindata.org/) when clicking on *"Browse by topic"*. I then map them onto the graph themes that we have seen above, focusing on groups that count more than 20 elements. The following donut chart displays the relative weight of each category in terms of how many graph it contains.<!-- i.e. Population and Demographic Change; Health; Energy and Environment; Food and Agriculture; Poverty and Economic Development; Education and Knowledge; Innovation and Technical Change; Living Conditions, Community and Wellbeing; Human Rights and Democracy; Violence and War -->```{r}#| warning: false#| fig-align: center#| fig-width: 10#| fig-height: 10aggreagte_picture <-read.csv("categorised_themes_ourworldindata.csv") %>%mutate(across(where(is.character), str_trim)) %>%group_by(category) %>%summarise(share =sum(share), n =sum(n)) %>%ungroup() %>%mutate(rank =dense_rank(desc(n)))# sum(aggreagte_picture$share) # We have retrieved 87% of the shares by considering only themes that group # more that 20 graphs.data <- aggreagte_picture %>%mutate(csum =rev(cumsum(rev(share))), ymin = csum - share, ymax = csum) %>%arrange(desc(category)) %>%mutate(midpoint = (ymin + ymax) /2,label_x =3.5, # x position for labelslabel_y = midpoint) # y position for labelscustom_palette <-c("#f72585ff","#b5179eff","#4cc9f0ff","#7209b7ff","#560badff","#480ca8ff","#3f37c9ff","#4361eeff","#4895efff","#3a0ca3ff")# ggplot(data, aes(ymax = ymax, ymin = ymin, xmax = 4, xmin = 3, fill = category)) +# geom_rect() +# coord_polar(theta = "y") +# scale_fill_manual(values = custom_palette) +# xlim(c(2, 4)) +# theme_void() +# theme(legend.position = "right",# plot.margin = margin(0, 0, 0, 0),# panel.margin = margin(0, 0, 0, 0)) +# labs(fill = "Category") +# geom_text(aes(x = label_x, y = label_y, label = n), color = "white", size = 4, hjust = 0.5)# # ggsave("donut_chart.png", width = 10, height = 10)# library(packcircles)## adata <- data.frame(category=paste("Group", letters[1:20]), n=sample(seq(1,100),20)) # apacking <- circleProgressiveLayout(adata$n, sizetype='area')# adata <- cbind(adata, apacking)# adat.gg <- circleLayoutVertices(apacking, npoints=50)# # ggplot() + # geom_polygon(data = adat.gg, aes(x, y, group = id, fill=as.factor(id)), colour = "black", alpha = 0.6) +# geom_text(data = adata, aes(x, y, size=n, label = category)) +# scale_size_continuous(range = c(1,4)) +# theme_void() + # theme(legend.position="none") +# coord_equal()## data <- data %>% select(category, n)# packing <- circleProgressiveLayout(data$n, sizetype='area')# data <- cbind(data, packing)# dat.gg <- circleLayoutVertices(packing, npoints=50)# # custom_palette <- c(# "#FF69B4", # Hot Pink# "#FF1493", # Deep Pink# "#DDA0DD", # Plum# "#DA70D6", # Orchid# "#BA55D3", # Medium Orchid# "#9370DB", # Medium Purple# "#8A2BE2", # Blue Violet# "#4B0082", # Indigo# "#4169E1", # Royal Blue# "#0000FF" # Blue# )# # ggplot() + # geom_polygon(data = dat.gg, aes(x, y, group = id, fill=as.factor(id)), colour = "black", alpha = 0.8) +# geom_text(data = data, aes(x, y, size=n, label = category)) +# scale_size_continuous(range = c(1,4)) +# scale_fill_manual(values = custom_palette) +# theme_void() + # theme(legend.position="none") +# coord_equal()```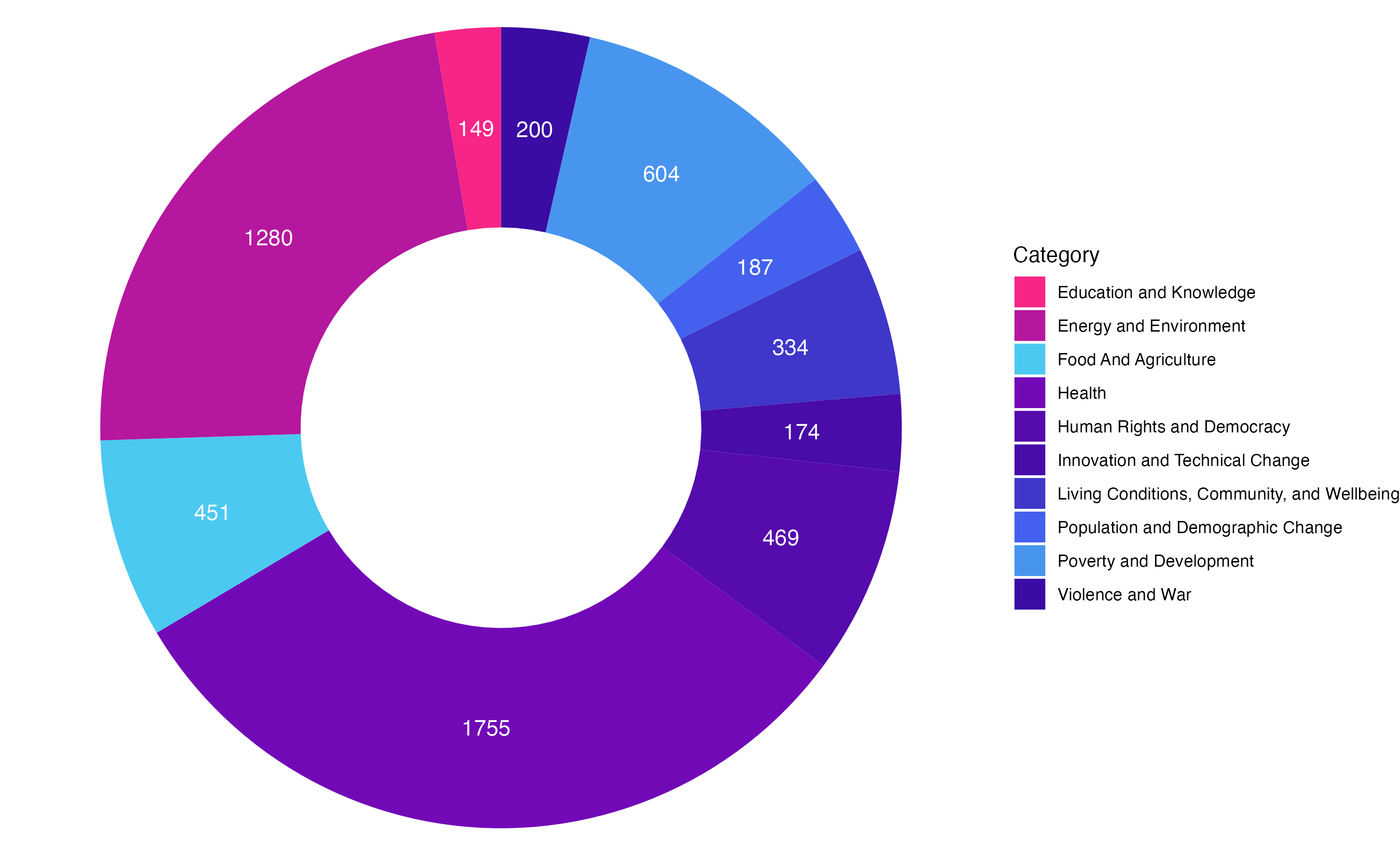<!-- Other classifications may also be useful, but they are beyonf the scope of this article. --><!-- For instance, there are 3 themes that focus on women only -- Women's Rights (n = 89), Women's Employment (n = 42), and Women in Politics (n = 32). Taken together, they would be the sixth largest theme. There are other examples, too. -->### Frequent wordsNow that we have all the graph titles, it may be worth counting how often words appear. We remove stop words and lemmatise them, too: this is relevant because very few people would care about how many times the words *of* and *the* appear. Similarly it makes sense to consider singular and plural forms as one, e.g. *country* and *countries*.```{r}word_counts <- bound_results %>%select(graph_title) %>%unnest_tokens(word, graph_title) %>%# Tokenize wordsanti_join(stop_words, by ="word") %>%# Remove stop wordsmutate(word_2 =lemmatize_words(word)) %>%count(word_2, sort =TRUE) # Count words and sort by frequency```The 5 most recurring words are: *share*, *death*, *rate*, *capita*, and *GDP*. 3 of these words (e.g. share, rate, capita) suggest that most graphs contain some sort of comparative element.### Are these positive or negative words?Why not performing some rudimentary version of sentiment analysis on them? Of course this is somewhat of a stretch because we are not dealing with actual sentences. The same word can have different meanings depending on what precedes or follows it. Similarly, there is a certain degree of subjectivity -- words might sound differently to different people. While it would feel pointless to identify the emotional tone of a neutral title, one could try to figure out what proportion of words are perceived as inherently related to negative or positive feelings. To do that, we evaluate the emotional color of words using the Bing method. It associates a binary positive/negative to each word.```{r}positive <-get_sentiments(lexicon ="bing") %>%filter(sentiment =="positive")negative <-get_sentiments(lexicon ="bing") %>%filter(sentiment =="negative")positive_words <- bound_results %>%select(graph_title) %>%unnest_tokens(word, graph_title) %>%# Tokenize wordsanti_join(stop_words, by ="word") %>%# Remove stop wordsmutate(word_2 =lemmatize_words(word)) %>%semi_join(positive) %>%count(word, sort =TRUE)negative_words <- bound_results %>%select(graph_title) %>%unnest_tokens(word, graph_title) %>%# Tokenize wordsanti_join(stop_words, by ="word") %>%# Remove stop wordsmutate(word_2 =lemmatize_words(word)) %>%semi_join(negative) %>%count(word, sort =TRUE)```We then create a pyramid plot that shows how frequently the 20 most common positive and negative words occur.```{r}#| fig-width: 8#| fig-height: 8#| warning: falsepositive_words <- positive_words %>%slice(1:20) %>%mutate(type ="Positive") %>%mutate(rank =row_number())negative_words <- negative_words %>%slice(1:20) %>%mutate(type ="Negative") %>%mutate(rank =row_number())sentiment_words <- positive_words %>%bind_rows(negative_words) %>%mutate(n =case_when( type =="Negative"~- n,TRUE~ n ))# Plot the pyramid chartggplot(sentiment_words, aes(x = rank, y = n, fill = type)) +geom_bar(stat ="identity", alpha =0.5) +geom_text(aes(label =str_to_title(word), y = n +ifelse(type =="Negative", -10, 10)),size =3, hjust =ifelse(sentiment_words$type =="Positive", 0, 1)) +scale_y_continuous(name ="Count", breaks =seq(-500, 500, 50), labels =abs(seq(-500, 500, 50))) +scale_fill_manual(name ="Sentiment", values =c("Positive"="#FF1493", "Negative"="royalblue" )) +coord_flip() +labs(x ="Rank", y ="Count", title ="") +ylim(-600, 100) +theme_minimal() +theme(legend.position ="bottom", axis.text.y =element_text(size =7)) ```The pyramid shows that the number of words with a positive connotation is much lower -- no wonder Economics was known as the dismal science! In other words, there is a tendency to focus on topics that are perceived as somewhat gloomier. Not only: given that bars are ordered by rank, this chart also makes clear that the most requent negative word is much more common than the most frequent positive one. This does not mean that the fine folks at [ourworldindata.org](https://ourworldindata.org/) are a bunch of pessimists. One can be an optimist and talk about themes that are mostly perceived as negative: after all, absolute poverty has been on the decline for decades, child mortality is incomparably lower today than it was during the Industrial Revolution, and GDP per capita skyrocketed during the 20th century. While there is reason to believe that Malthus is *still* wrong, this is not to say that there are no challenges ahead.### A network of wordsWe can also use these data to explore some concepts in network analysis. Let us consider all the corpus of graph titles. How often do words appear together? How do they relate to each other? Are there any clusters of words that stand out? Let us do that visually.```{r}#| warning: false#| fig-align: center#| fig-width: 10#| fig-height: 10tokenized_df <- bound_results %>%select(graph_title) %>%unnest_tokens(word, graph_title, drop = F) %>%# Tokenize words from the 'titles' columnanti_join(stop_words, by ="word") %>%pairwise_count(word, graph_title, sort =TRUE, upper =FALSE) %>%filter(n >10)# tokenized_df %>%# graph_from_data_frame() %>%# ggraph(layout = "fr") + # "kk", "fr", "dh"# geom_edge_link(aes(edge_alpha = n, edge_width = n), edge_colour = "cyan4") +# geom_node_point(size = 5) +# geom_node_text(aes(label = name), repel = TRUE, point.padding = unit(1, "lines")) +# theme_void()vertices <- tokenized_df %>%pivot_longer(names_to ="key", values_to ="value", 1:2) %>%select(- key) %>%group_by(value) %>%summarise(n =sum(n)) %>%ungroup()gf <- tokenized_df %>%graph_from_data_frame(vertices = vertices) gf %>%ggraph(layout ="dh") +# "kk", "fr"geom_edge_link(aes(edge_alpha = n, edge_width = n), edge_colour ="royalblue") +geom_node_point(aes(size = n)) +geom_node_text(aes(label = name), repel =TRUE, point.padding =unit(1, "lines")) +theme_void()```Each vertex is scaled according to how often each word appears. Links are larger and darker depending on how often word pairs are found together. The word *share* is very central. It often tandems with *population*, *children*, *living*, *people*, and *GDP*. It cuts through all the 10 categories we saw earlier. *GDP* is tightly tied to *capita*.We can also decide to only show clusters that have a minimum level of correlation, i.e. words that are almost invariably found together.```{r}#| warning: false#| fig-align: center#| fig-width: 10#| fig-height: 10tokenized_dfa <- bound_results %>%select(graph_title) %>%unnest_tokens(word, graph_title, drop = F) %>%# Tokenize words from the 'titles' columnanti_join(stop_words, by ="word") %>%group_by(word) %>%filter(n() >=10) %>%pairwise_cor(word, graph_title, sort =TRUE, upper =FALSE)tokenized_dfa %>%filter(correlation > .5) %>%graph_from_data_frame() %>%ggraph(layout ="fr") +geom_edge_link(aes(edge_alpha = correlation, edge_width = correlation), edge_colour ="royalblue") +geom_node_point(size =5) +geom_node_text(aes(label = name), repel =TRUE,point.padding =unit(0.2, "lines")) +theme_void()```Pairs like *paid leave*, *artificial intelligence*, and *air pollution* immediately pop out.